An AI agent for the 2021 Australian Census.
Ask the Census anything in plain English and get a sourced, charted, verifiable answer. Built end-to-end to keep my hands on the implementation reality of the agentic systems I increasingly advise on.
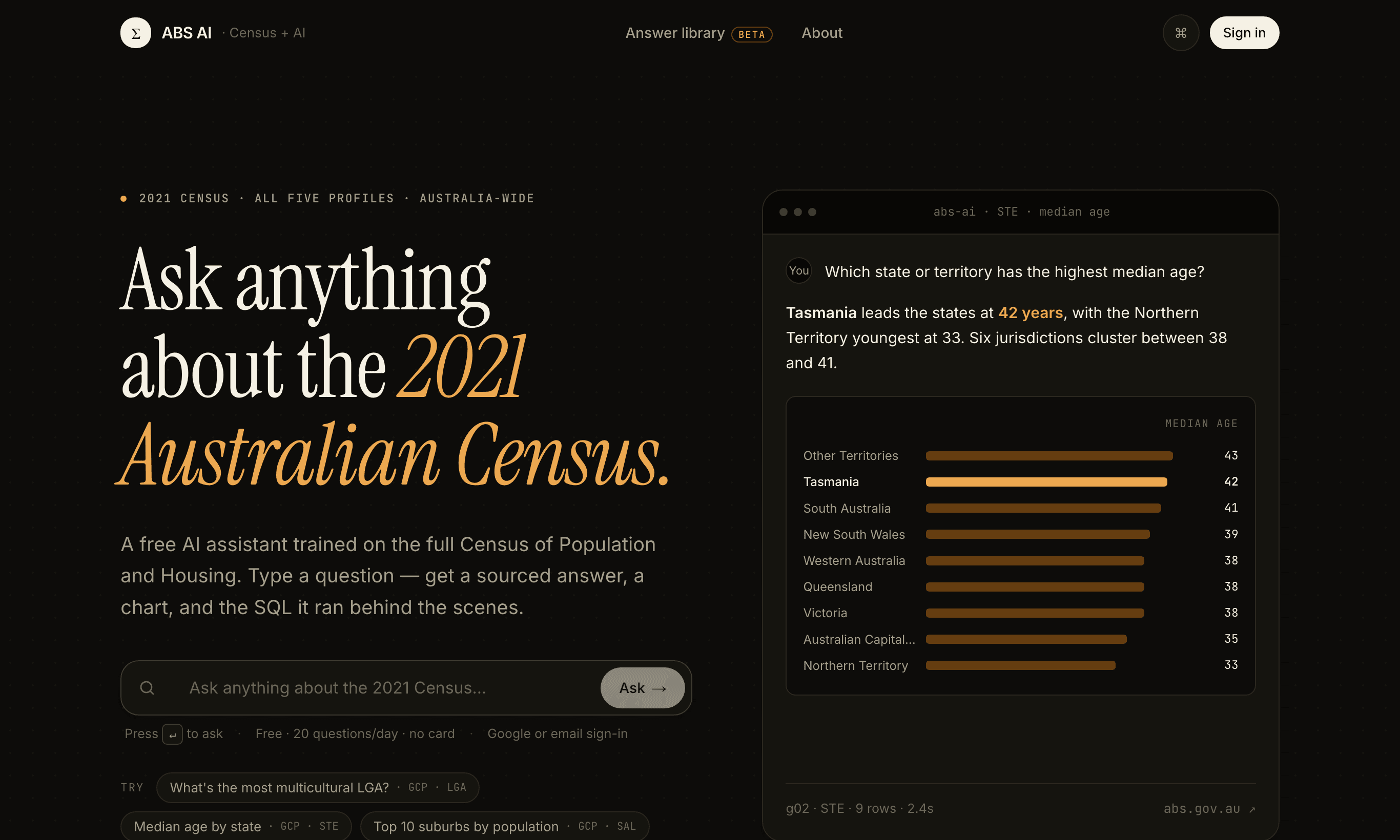
absai.com.au is a working AI agent over the entire 2021 Australian Bureau of Statistics Census — all five profiles, 22 GB, 409 tables, around 17,000 columns semantically indexed. You ask a question in plain English (“which state has the highest median age?”, “how multicultural is Marrickville?”) and it answers with an editorial sentence, a chart, the underlying data, and a citation back to the exact ABS table. It’s free, civic-tech, live since May 2026 — and still in active beta as I keep extending what it can answer.
Two reasons. First, reps. The fastest way to understand agentic data products is to build a real one end-to-end — schema, ingestion, natural-language-to-SQL, a production frontend, a public deploy. Each layer surfaces tradeoffs you can’t get from reading docs. As a CTO advising on these systems, strategy is sharper when you’ve shipped something recently.
Second, the data deserved it. The ABS publishes excellent DataPacks and a TableBuilder UI — but neither is “ask in plain English.” That gap is exactly where a well-built agent earns its keep, provided every answer stays sourced and verifiable rather than a confident guess.
The retrieval is two-stage: shortlist the relevant tables by keyword coverage, then run pgvector cosine similarity over column-description embeddings to pick the ~30 most relevant columns for the question. A hand-curated semantic layer pins the canonical measures so the model doesn’t drift to near-synonyms. Gemini 2.5 writes the SQL; a deterministic Python chart builder picks the visual; a structured response schema carries the answer, data, chart and citation to the frontend as one typed contract.
It runs across three cloud regions because that’s what the platforms allow: the agent on Vertex AI Agent Engine in Melbourne, the database on Supabase in Sydney, and Gemini routed globally. A one-command in-place redeploy keeps the agent’s resource id stable, so the frontend’s configuration never has to change.
A question in plain English
/api/chat — JWT-verified, rate-limited, streamed
call_postgres_agent — deterministic Python orchestration
postgres_nl2sql — semantic layer YAML + pgvector cosine
run_postgres_query — read-only, 20s timeout
census_2021 — 409 tables, immutable
metadata — columns + embeddings (retrieval index)
Deterministic Python beats LlmAgents for orchestration. The biggest accuracy win in the whole project was a refactor that removed an LLM. A wrapper agent was paraphrasing the user's question on its way to the SQL layer — and getting it wrong often enough to score 1-in-3 on a consistency probe. Replacing it with plain Python that forwards the verbatim question took the same probe to 5-in-5. Let LLMs be creative where creativity matters; let code be deterministic everywhere else.
A hand-curated semantic layer beats better embeddings. pgvector retrieval gets you ~85% of the way to the right column. The last 15% — the canonical measures like median age or average household size — keeps drifting to near-synonyms whose text descriptions are almost identical. A small YAML file pinning ~47 measures to their exact column, matched by alias, fixed it. Maybe 30 minutes to author a measure; pays back the first time the right answer pops out instead of a plausible wrong one.
The response schema is the contract. After the third “let me regex this out of the streamed prose” hack, I made the agent's response a real Pydantic schema, hand-mirrored in TypeScript on the client. Every UI iteration became “add a field” instead of “find the right pattern in the text.” And when the model occasionally streams nothing, the structured payload still drives the chart, the data table and the citation — the user sees a partial answer, not a blank one.
Error and clarification aren't “answers with missing data.” A single enum — answer | clarification | error — drives three distinct card layouts on the frontend. Before that, greetings and failures rendered with the full data scaffold (chart slot, table, citation row) all empty, and looked like broken answers. The smallest schema change paid back the most.
Serverless lifecycle is a primary design constraint. Three production bugs traced to the same wrong assumption: that a Vercel function is alive whenever you want it to be. It isn't — it lives only as long as something consumes its response. The rules that stuck: wrap every stream write in a guard that survives a closed connection, drain the upstream agent to completion regardless of the client, and await every database write that matters before the handler returns. Never fire-and-forget.
RLS and GRANT are a pair, always. Postgres checks role-level GRANTs before row-level security policies even run, and applies the SELECT policy to an INSERT…RETURNING. Two debugging sessions went to tables that had correct RLS but no GRANT, surfacing as cryptic “permission denied” and “new row violates policy” errors. Every new-table migration now ships enable-RLS, the policies, and the grant as one template.